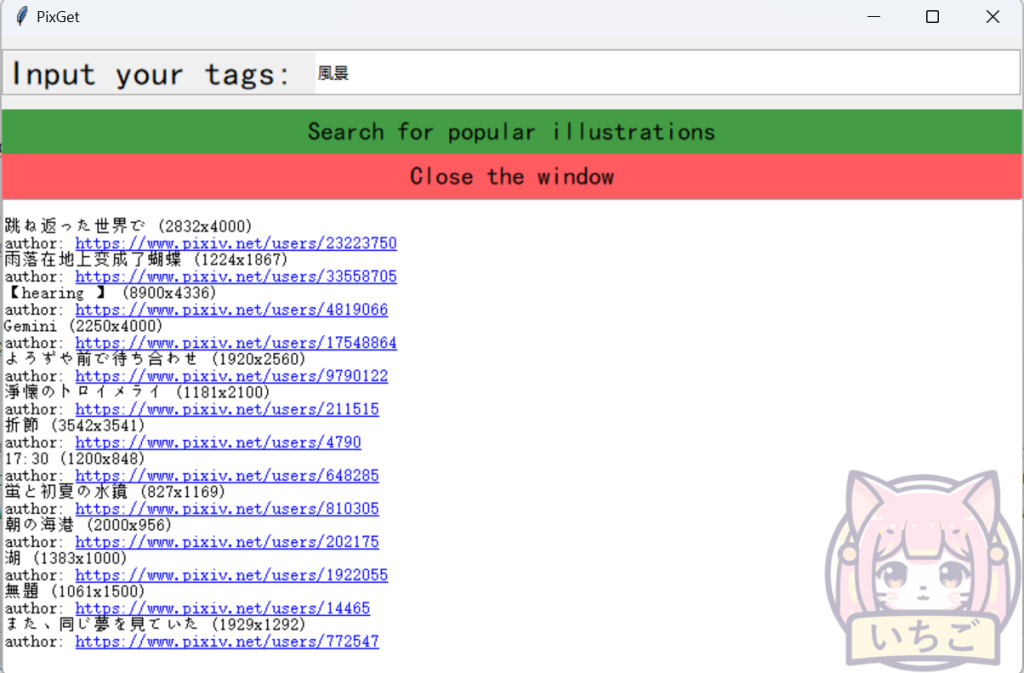
包含Pixiv爬虫方法pixivCrawler()以及用tkinter制作的简易GUI。导出的结果包含两部分:
- (Pycharm的Run界面)该tag下最近的作品和作者链接,具体多少个博主忘了;
- (Pycharm的Run界面 + Tkinter的GUI界面)该tag下热度最高的作品和作者链接,共10个。
Python
# 抓取Pixiv特定tag下的热门插画信息
# 抓取前请先开启代理,确保Pixiv可以正常访问
import re
import time
import random
import requests
import urllib.parse
import tkinter as tk
from webbrowser import open as webopen
def linkOpen(yValue, authorUrlList):
judgeNum = (yValue - 28) / 25.6
webopen(authorUrlList[int(judgeNum)])
# Core code
def pixivCrawler():
tag = tagVar.get()
text.delete(1.0, tk.END)
# tag转码
quoteTag = urllib.parse.quote(tag)
# 从网页版搜索的地址,响应中不包含有效信息
# url = 'https://www.pixiv.net/tags/' + quoteTag + '/artworks?s_mode=s_tag'
# 真正的搜索地址,响应中包含有效信息
url = 'https://www.pixiv.net/ajax/search/artworks/' + quoteTag
headers = {
# 此处的原cookie值已被博主刻意篡改,请自行更换cookie值
'cookie': 'first_visit_datetime_pc=2022-10-09+20%3A11%3A52; p_ab_id=1; p_ab_id_2=2; p_ab_d_id=1266910075; yuid_b=N4kJVJg; privacy_policy_notification=0; a_type=0; b_type=1; _gcl_au=1.1.1476230386.1669184782; _gid=GA1.2.777450877.1669184785; device_token=15acd5010b5630ba4e3d5ed76e3f46d5; QSI_S_ZN_5hF4My7Ad6VNNAi=v:0:0; first_visit_datetime=2022-11-23+22%3A46%3A35; privacy_policy_agreement=5; tag_view_ranking=RTJMXD26Ak~uusOs0ipBx~Lt-oEicbBr~jhuUT0OJva~Oa9b6mEc1T~BcgdSrD7gc~QLvl6kE4lC~9ODMAZ0ebV~1Xn1rApx2-~mFW848gK6h~EkOeSssAmi~UdsOa6tZrT~sOBG5_rfE2~LJo91uBPz4~KvAGITxIxH~nQRrj5c6w_~oLPD5rNe0R~PTyxATIsK0~uW5495Nhg-~gCB7z_XWkp~XwbsX1-yIW~Wxk4MkYNNf~LpjxMAWKke~PwDMGzD6xn~pa4LoD4xuT~QjJSYNhDSl~_Jc3XITZqL~kP7msdIeEU~kZyLZDtxMx~Tb7S5ldFeI~Lriz5mgtO4~7Y-OaPrqAv~nSgabm-jWl~Xs-7j6fVPs~eVxus64GZU~DuCdp8i1kQ~K8esoIs2eW~wKl4cqK7Gl~5CuZ1ZlUzm~SoxapNkN85~-aAmH5tJol~u0Jb317RoC~3SAZKPd9Ah~xdGB9etdrA~FQHUiBZOQu~dRqI60OhDM~tf0x8pUL6L~a0DrPSAsM5~-qP3pM5H97~OlmMhl04U3~jyw53VSia0~t2ErccCFR9~0c3mrf8bTA~OrOiBO3FTi~dqqWNpq7ul~9vsCdQ-g9S~mLrrjwTHBm~RybylJRnhJ~Ie2c51_4Sp~uU8LRrGXsr~NIg4rAP1ON~HlwTcYEOCZ~8XX2eqWqNX~VLDgZNuX1x~VSI71mhgdM~GX7J0_CPTv~CRyGCFuXbN~Kn4NerembX~KIeuAXEMqc~_p9--cj6dL~qtVr8SCFs5~ZT3IraNy3Q~Mg6bq-SpX8~LoDIs84uJh~2pZ4K1syEF~GOoxrZe8O4~5oPIfUbtd6~L52KPOAqP3~2KIjZGVMwC~tgP8r-gOe_~xwCzBAUYlW~nydBByWrjM~F5CBR92p_Q~d2oWv_4U1L~RFVdOq-YjA~a-yCMcqYxL~AgZY8GdPPj~RYfWH9_3Ug~P0AYTSS8i4~gqKsadmiG0~eRHUOfrCWe~EUwzYuPRbU; login_ever=yes; PHPSESSID=88404626_haIFeWKuoevSlAgN9CQmUc70dPEkFJ7L; _ga_MZ1NL4PHH0=GS1.1.1669302621.2.1.1669302647.0.0.0; c_type=22; __cf_bm=3dRVtCxuLXAnFAErWkvQABeqDEv0YrodfrZEawNmzlg-1669302651-0-AedQOCEc7rsh3qexaf0hd+d2w7NVKLSg+ib00y2V1B6RiW0gejPC4k7q8ViM1h7BN+FuFyJH970gfjJxv6ENex/N8U5PKzeT28O2wh9wLmbo; _ga_75BBYNYN9J=GS1.1.1669300848.7.1.1669302652.0.0.0; _ga=GA1.2.1603734869.1665313928',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56'
}
response = requests.get(url=url, headers=headers)
imgInfoInter = re.findall('"illustManga":(.*?)"popular":(.*)', response.text)
print('-----------Search result for tag [%s]-----------' % (tag))
subTitle = ['Part 1\t<recent illustrations="">', 'Part 2\t<popular illustrations="">']
for i in range(2):
print('---------------------------------------\n', subTitle[i], tag, '\n')
imgInfo = re.findall(
'"id":"(.*?)","title":"(.*?)","illustType".*?"userId":"(.*?)","userName".*?"width":(.*?),"height":(.*?),"pageCount',
imgInfoInter[0][i])
authorUrlList = []
linkRecorder = 0
for imgId, title, userId, width, height in imgInfo:
try:
imgTitle = title.encode('utf-8').decode('unicode_escape')
imgUrl = 'https://www.pixiv.net/artworks/' + userId
authorUrl = 'https://www.pixiv.net/users/' + userId
if i == 1:
authorUrlList.append(authorUrl)
text.insert(tk.INSERT, '\n' + imgTitle + ' (' + width + 'x' + height + ')\nauthor: ')
text.tag_configure('link' + authorUrl, foreground='blue', underline=True)
text.insert(tk.INSERT, authorUrl, 'link' + authorUrl)
# '<button-1>': 鼠标左键
text.tag_bind('link' + authorUrl, '<button-1>', lambda event: linkOpen(event.y, authorUrlList))
if linkRecorder < (len(authorUrlList) - 1):
linkRecorder += 1
print('%s (%sx%s)\tlink: %s\tauthor: %s' % (imgTitle, width, height, imgUrl, authorUrl))
# time.sleep(random.randint(5, 10))
except Exception:
continue
# 关闭页面
def windowDestroy():
root.destroy()
root = tk.Tk()
root.geometry('800x500+500+300')
root.title('PixGet')
inputFrame = tk.LabelFrame(root)
inputFrame.pack(pady=10, fill='both')
tk.Label(inputFrame, text='Input your tags: ', font=('黑体', 20)).pack(side=tk.LEFT)
tagVar = tk.StringVar()
tk.Entry(inputFrame, width=100, relief='flat', textvariable=tagVar).pack(side=tk.LEFT, fill='both')
tagVar.set('風景')
tk.Button(root, text='Search for popular illustrations', font=('黑体', 15), relief='flat', bg='#449d44',
command=pixivCrawler).pack(fill='both')
tk.Button(root, text='Close the window', font=('黑体', 15), relief='flat', bg='#FF5B60', command=windowDestroy).pack(
fill='both')
text = tk.Text(root, width=100, height=100, undo=True, autoseparators=False)
text.pack(fill='both')
root.mainloop()
</button-1></button-1></popular></recent>注:因为Pixiv靠作品筛选赚钱,直接大量查找作品链接很快就会被ban,不要多问博主为什么知道!所以如果介意的话,请间歇地使用,勿在短时间内制造大量请求。
Tkinter查询完成后的界面如下(已经移除了作品链接,因为博主无法直接访问):