
先导
假设检验的定义可以是:用来判断样本与样本、样本与总体的差异是由抽样误差引起,还是由本质差别造成的统计推断方法。
或者用更简单的话说,假设检验的目的就是,看某个命题是否在“吹牛”,如果试验结果显示出和该命题非常不一致(即p值超出了允许的显著性水平α)的结果,则有理由怀疑这个命题的真实性(即拒绝原假设)。可以这样做的原因是,如果原假设正确,那么一次试验就出现这种现象的概率是很小的,甚至可以认为是不可能的,这个时候当然可以认为掌握了相当有效的证据以拒绝原假设。
当然,在原假设正确的情况下,上述现象出现概率极小并不意味着概率就是0。因此上述拒绝原假设的过程也可能会犯错误,这个错误的概率就是显著性水平α,这个错误被称作第I类错误(或弃真错误、α错误)。这个错误的含义也可以说成:实际上新策略(即备择假设H1)无效,但我们的试验却显示其有效,此时犯了弃真(即拒绝正确的原假设H0)的错误。
显然,有弃真就有取伪,这个错误被称作第II类错误(或取伪错误、β错误)。仿照上面的定义,取伪错误即是指实际上备择假设有效,但试验却显示无效,因而保留了错误的原假设。
假设检验的类型有很多种,在常见的A/B测试中包含z检验、t检验和χ2检验。以下就针对A/B测试中涉及的这三种检验(统计推断)进行详细说明。
常用统计推断
参考文献:
https://zhuanlan.zhihu.com/p/346602966
https://blog.csdn.net/robert_chen1988/article/details/103378351
https://www.cnblogs.com/HuZihu/p/11442833.html
z检验(z test)
含义
用z分布(即标准正态分布)理论来推断差异发生的概率,从而判定平均数的差异是否显著。
z检验通常是针对大样本的,统计学中认为样本量n不小于30就算大样本(但在数学上大样本指的是趋于无穷大)。或者即使是小样本,但是知道其服从正态分布,并且知道总体分布的方差时,也可以用z检验。
应用方法
statsmodels.stats.weightstats库的ztest(x1, x2=None, value=0, alternative='two-sided')方法。alternative参数可选值还包括'larger'和'smaller',分别用于表达备择假设大于和小于value值的情况(单尾检验)。
import statsmodels.stats.weightstats as sw
arr_1 = [23, 36, 42, 34, 39, 34, 35, 42, 53, 28, 49, 39, 46, 45, 39, 38, 45, 27, 43, 54, 36, 34, 48, 36, 47, 44, 48, 45,
44, 33, 24, 40, 50, 32, 39, 31]
arr_2 = [41, 34, 36, 32, 32, 35, 33, 31, 35, 34, 37, 34, 31, 36, 37, 34, 33, 37, 33, 38, 38, 37, 34, 36, 36, 31, 33, 36,
37, 35, 33, 34, 33, 35, 34, 34, 34, 35, 35, 34]
# 以下试验置信度均取0.05
# 1 检测样本arr_1均值是否为39
result_1 = sw.ztest(arr_1, value=39)
# result_1 = (0.3859224924939799, 0.6995540720244979)
# 此时接受原假设,认为均值是39
# 2 检测样本arr_1均值是否大于等于39
result_2 = sw.ztest(arr_1, value=39, alternative='smaller')
# result_2 = (0.3859224924939799, 0.650222963987751)
# 此时接受原假设,认为均值大于等于39
# 3 检测arr_1和arr_2两个样本的均值是否相等
result_3 = sw.ztest(arr_1, arr_2, value=0)
# result_3 = (3.775645601380307, 0.0001595937672736755)
# 此时拒绝原假设,认为两个样本的均值不相等t检验(Student's t test)
含义
用t分布理论来推断差异发生的概率,从而判定两个平均数的差异是否显著。
t检验通常是针对小样本的,但是A/B测试通常样本量很大,因此这点不是太重要。
应用方法
scipy.stats库中的三个方法:
ttest_1samp(a, popmean):用于单样本t检验。ttest_ind(a, b, equal_var=True):用于独立样本的t检验,两组数据收集于不相关的群体。equal_var为True时表示两个样本有相同的方差,为False时表示两个样本的方差不同,此时使用合并方差。ttest_rel(a, b):用于配对样本的t检验,两组数据来自于相同的群体,在不同的时间点或不同的条件下收集。主要用来比较在某种干预或条件改变前后,同一组受测者的平均分数是否有显著差异。
import scipy.stats as st
a = [99.3, 98.7, 100.5, 101.2, 98.3, 99.7, 99.5, 102.1, 100.5]
b = [91.1, 93.7, 93.6, 96.1, 94.3, 92.2, 94.0, 95.7, 97.1]
# 以下试验置信度均取0.05
# 这些试验都是双尾检验,如果是单侧检验,获得的p值需要换算一下
# 1 检测样本a的均值是否为100
result_1 = st.ttest_1samp(a, 100)
# result_1 = Ttest_1sampResult(statistic=-0.054996133220328265, pvalue=0.9574902045208937)
# 此时接受原假设,认为均值是100
# 2 检测a和b两个相互独立的样本的均值是否相等
result_2 = st.ttest_ind(a, b, equal_var=False)
# result_2 = Ttest_indResult(statistic=7.723221821038956, pvalue=2.4331092243754622e-06)
# 此时拒绝原假设,认为两个样本的均值不相等
# 3 若b是a的配对样本,则此时使用ttest_rel()执行上述检测
result_3 = st.ttest_rel(a, b)
# result_3 = Ttest_relResult(statistic=10.845107419335658, pvalue=4.617509769582176e-06)
# 此时拒绝原假设,认为两个样本的均值不相等χ2检验(chi square test)
含义
又称卡方检验。比较常见的检验对象为拟合优度(用χ2分布理论来检验样本数据与总体分布是否吻合,从而判定样本偏差是否显著。可以用于检验抽样是否合理)和独立性(用于检查两个分类变量之间是否独立,适用于频数数据)。
应用方法1:卡方拟合优度检验
利用scipy.stats中的chisquare(f_obs, f_exp=None)进行。
假设我们想要检验一个骰子是否公平。一个公平的六面骰子每一面出现的概率应该是相等的,即每一面出现的期望频数应该是相同的。如果我们掷了骰子600次,理论上,每一面出现的次数应该是100次。但我们实际观察到的频数为:
- 1点:95次
- 2点:105次
- 3点:98次
- 4点:110次
- 5点:93次
- 6点:99次
此时我们可以使用χ2拟合优度检验,看看实际观察到的频数与理论上的频数是否有显著差异。设置试验的置信度为0.05。
from scipy.stats import chisquare
# 实际观察频数
observed_frequencies = [95, 105, 98, 110, 93, 99]
# 期望频数(如果骰子是公平的,每一面出现的次数)
expected_frequencies = [100, 100, 100, 100, 100, 100]
# 执行卡方拟合优度检验
chi2_stat, p_value = chisquare(observed_frequencies, f_exp=expected_frequencies)
print("Chi2 Statistic:", chi2_stat) # 卡方统计量:2.04
print("P-value:", p_value) # p值:0.843583055224107
# 此时接受原假设,认为这个骰子是公平的应用方法2:卡方独立性检验
利用scipy.stats中的chi2_contingency(observed)进行。
假设我们有一个关于学生是否喜欢体育课的调查,分为男生和女生,我们想要检验性别(男、女)和对体育课的喜好(喜欢、不喜欢)之间是否独立。
| 性别/喜好 | 喜欢 | 不喜欢 |
|---|---|---|
| 男生 | 20 | 30 |
| 女生 | 25 | 25 |
from scipy.stats import chi2_contingency
# 创建一个二维数组来表示上表的数据
data = [[20, 30], [25, 25]]
# 执行卡方检验
chi2, p, dof, expected = chi2_contingency(data)
print("Chi2 value:", chi2) # 卡方值:0.6464646464646464
print("P-value:", p) # p值:0.4213795037428696
print("Degrees of freedom:", dof) # 自由度:1
print("Expected frequencies:", expected) # 在原假设下期望的频数分布:[[22.5 27.5] [22.5 27.5]]
# 此时接受原假设,认为这两个喜好之间是独立的效应量
显著性检验的一个局限性在于,其分析而得的统计显著性并不能反映实际重要性(业务价值)。
即使差异是统计显著的(p值很小),我们也想知道这个差异在实际中的重要性如何。为解决这一问题,可以计算效应量(Effect Size)。可用于表示效应量的指标很多,具体选择取决于研究对象,选择时使该指标能够反映真实存在的某种差异即可。
但对于某些抽象指标,也可以直接选用一些约定的效应量,如效应量d(Cohen's d,标准化平均差),其给出了两组之间差异的量化度量:两组的平均值相差d个标准差。
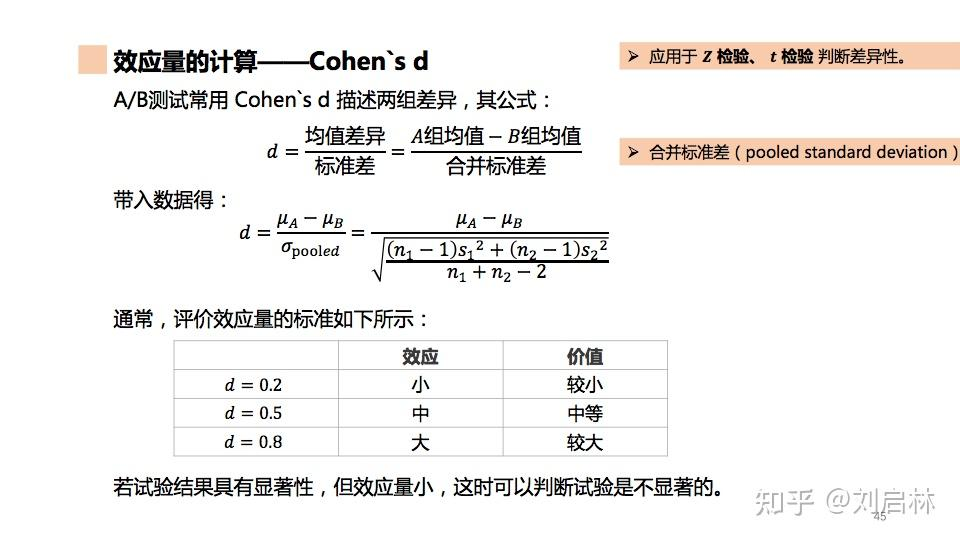
以及,可以进一步利用MDE(Minimum Detectable Effect,最小可检测效应)来辅助这一结果。MDE即为实验设计能够可靠检测到的效应量的阈值。

当效应量d大于MDE时,这表示实验观察到的效应量超过了能够可靠检测到的最小效应。即,此时实验组、对照组间的差异是实际重要的。

