前情提要:
PCA的局限性
非线性关系
PCA是基于线性代数的方法,它通过线性变换将高维数据投影到低维空间中,因此它只能有效捕捉数据中的线性关系。
如果数据存在复杂的非线性结构,PCA可能无法很好地表现出来。比如,考虑一个在高维空间中呈现螺旋形状的数据集,PCA会将其投影成一个线性的形状,而丢失了数据的非线性结构。
局部信息
PCA的主要目标是找到能够最大限度保留数据方差的方向,也就是说,它关注的是数据的全局结构。换句话说,PCA试图在低维空间中保留尽可能多的信息量。
这种全局结构的保留往往会忽略局部细节。对于一些任务来说,局部邻近关系可能更加重要。例如,在数据可视化中,我们通常希望保留数据点之间的局部邻近关系,以便能够更直观地观察数据的分布和聚类结构。
t-SNE
简介
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种降维算法,主要用来将高维数据投影到低维空间中,通常是二维或三维,以便可视化。它的核心思想是保持高维空间中数据点之间的局部距离关系。
其执行流程为:
- 在高维空间中,计算每对数据点之间的相似度,这个相似度通常用正态分布来衡量。
- 在低维空间中,用t分布(t-distribution)来衡量数据点之间的相似度。t分布的尾部比正态分布更“重”,这一尾部可以更好地模拟相距很远的距离。
- 通过最小化高维和低维空间中相似度分布的差异,找到一个低维表示,使得原数据的局部结构能尽可能保留。
画个图对比一下t分布(柯西分布)和正态分布(高斯分布)的图象:
Python
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import cauchy, norm
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 定义x的范围
x = np.linspace(-10, 10, 1000)
# 计算柯西分布和高斯分布的概率密度函数,此处均用标准分布方便对比
cauchy_pdf = cauchy.pdf(x) # 标准t分布
norm_pdf = norm.pdf(x) # 标准正态分布(z分布)
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(x, cauchy_pdf, label='Cauchy Distribution (标准t分布)', color='blue', linestyle='--')
plt.plot(x, norm_pdf, label='Gaussian Distribution (z分布)', color='red', linestyle='-')
plt.title('Comparison of Cauchy Distribution and Gaussian Distribution')
plt.xlabel('x')
plt.ylabel('Density')
plt.legend()
plt.grid(True)
plt.show()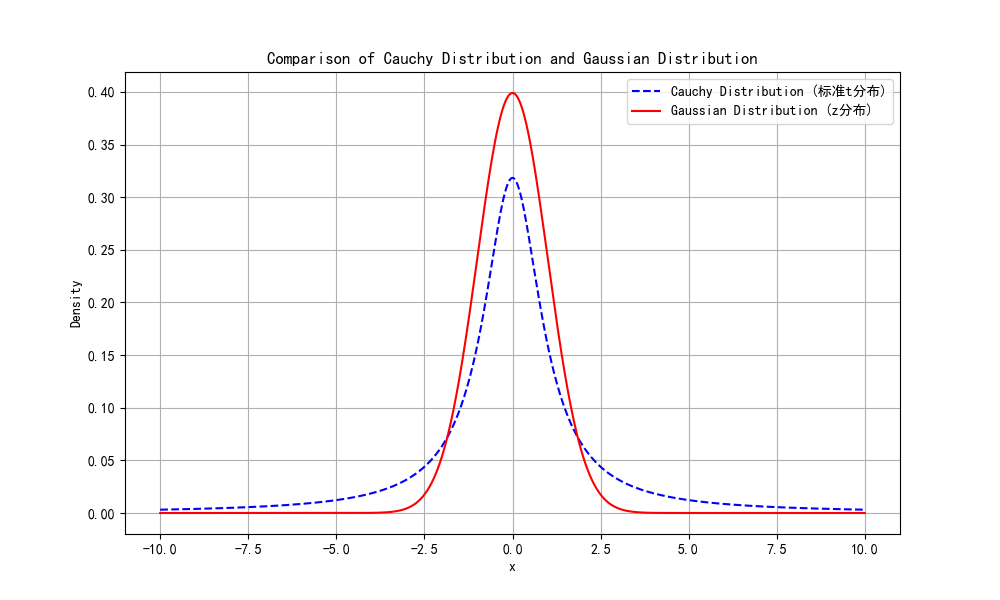

t-SNE更多是用来可视化高维数据的。它在保持局部结构上很擅长,所以可以把高维数据“变成”2D或3D的漂亮图形,方便我们理解数据的分布和聚类情况。但它不是线性变换方法,也就是说,你用它转换后的数据不适合直接用于其他机器学习模型。(^-^)

嗯……可视化效果也许是t-SNE最大的优点了。
如果你需要进行数据转换,比如用于降维以后的数据再做分类或回归,PCA可能更合适。所以啊,根据你的具体需求来选择合适的方法最重要啦! (。・ω・。)ノ♡
Scikit-learn中的TSNE类
用sklearn自带的MNIST手写数字数据集(Digits数据集)展示该类的使用方法。
Python
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data # 维数8*8=64
y = digits.target
tsne = TSNE(n_components=2, random_state=42) # 感觉t-SNE给一个确定的random_state还是比较重要的
X_2d = tsne.fit_transform(X)
plt.figure(figsize=(6, 5))
colors = 'r', 'g', 'b', 'c', 'm', 'y', 'k', 'pink', 'orange', 'purple'
for i, c in zip(range(10), colors):
plt.scatter(X_2d[y == i, 0], X_2d[y == i, 1], c=c, label=str(i))
plt.legend()
plt.show()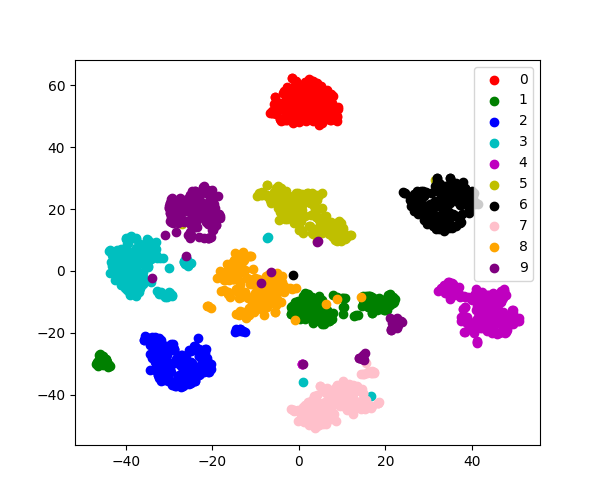
UMAP
简介
UMAP(Uniform Manifold Approximation and Projection)也是一种降维算法,可以将高维数据映射到低维空间,同时尽量保持原数据的结构。
其主要思想为:
- 构建邻接图:UMAP在高维空间中构建一个邻接图,用以表示数据点之间的邻近关系。各点的近邻点的数量是可以调整的,更少的近邻点意味着更精确的结构细节,更多则意味着广泛的准确性。
- 优化布局:在低维空间中寻找一个新的布局,使得上述邻接图中的邻近关系尽可能保留下来。这个过程类似于一个优化问题,通过不断调整低维空间中点的位置来最小化损失函数(Cross-Entropy)。
UMAP的优点是它可以很好地捕捉数据的局部结构,同时也能保留数据的全局结构。而且,相比于其他降维算法,如t-SNE,UMAP通常速度更快,并且具有更好的可扩展性。总的来说,UMAP降维后的数据是适合用于进一步的数据分析的。
Umap-learn中的UMAP类
同样使用Digits数据集展示该类的使用方法。
Python
from umap import UMAP
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
umap = UMAP(n_neighbors=150, n_components=2) # 调整n_neighbors很重要
X_2d = umap.fit_transform(X)
plt.figure(figsize=(6, 5))
colors = 'r', 'g', 'b', 'c', 'm', 'y', 'k', 'pink', 'orange', 'purple'
for i, c in zip(range(10), colors):
plt.scatter(X_2d[y == i, 0], X_2d[y == i, 1], c=c, label=str(i))
plt.legend()
plt.show()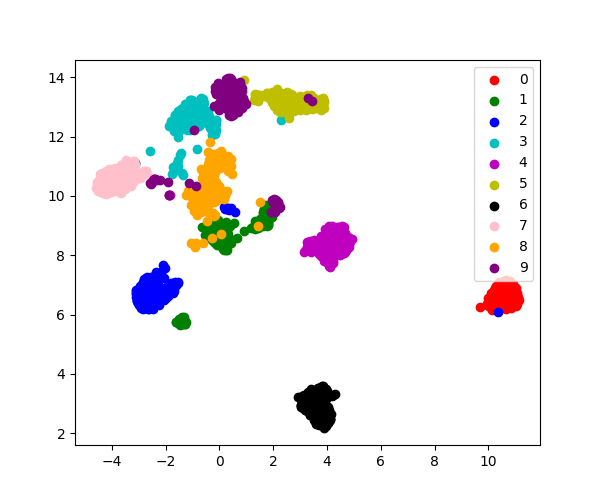
小插曲
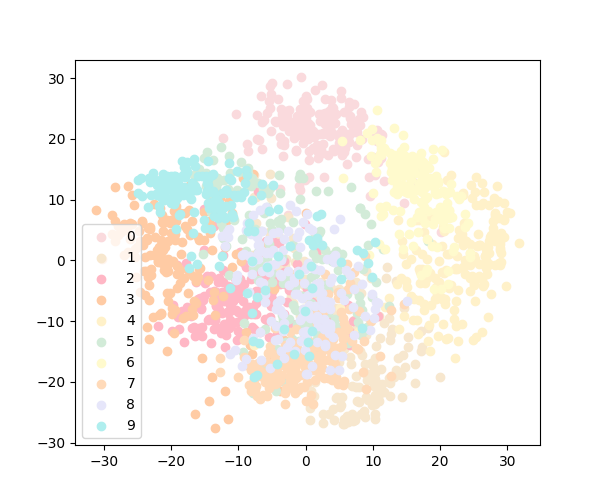
嗯……突然想看看PCA的结果会是什么样。
……
博主品鉴中……
……
……不是密恐都觉得哈人。换个色系好了。
| #FADADD | #F7E7CE | #FFB7C5 | #FFCBA4 | #FFF1C9 |
| #D2EBD8 | #FFFACD | #FFDAB9 | #E6E6FA | #AFEEEE |