
前置算法:HH(Highway Hierarchies)
利用道路本身存在不同等级这一固有性质,构建了一种层级结构,该层级结构不是简单利用道路等级的人为划分,而是利用局部最短路径查询提取highway构成下一级子图,然后进行迭代,生成多层级结构。
如何构建层级结构
在原始图G中利用Dijkstra局部查询获得局部最短路径,从每条最短路径中提取一条关键路径(highway),构成下一级图G’,通过特征提取对G’进行压缩后,反复执行上述过程,直至最后一个层级子图只剩下一个点或者极少边。
如何查询
在各层级之间对于每一对相同的顶点增加一条权值为0的有向边,保证查询能够从本级图顺利进入下一级图;在每一层内进行局部双向Dijkstra算法,未找到最短路径则通过权值为0的边进入下一级图查询,重复上述过程,直到处理完所有相遇点,找到最短路径。
CH(Contraction Hierarchies, 层次收缩)算法简介
CH是对HH(Highway Hierarchies)的改进和扩展,HH可以用一定的方法构造路网分层,相比人为采用道路功能等级分层效果更好;CH相比于HH,具有更好的处理有向图的思路、更小的空间开销、更快的查询速度、更严谨的理论支持。
CH主要解决的问题
路网分层:CH算法使用节点收缩预处理过程创建一个层次结构,使得路网中每个节点都拥有了唯一的重要性层次(优先级)。
精确结果:节点层次的划分不会影响最终的搜索结果;相比启发式算法,CH可以避免陷入局部最优。
搜索速度:在执行搜索时,双向搜索只需要向层次升高的方向进行,大幅提高了查询速度。
CH算法原理:预处理
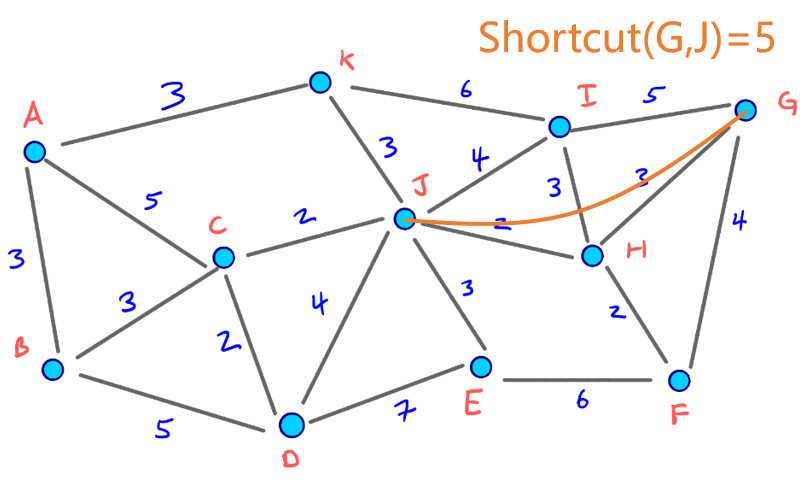
注:本节所选演示图片来自https://jlazarsfeld.github.io/ch.150.project/sections/10-ch-query/
单次收缩(Contraction)过程
一次收缩完成后,会形成排除了目标节点并添加了快捷边的子图,用于下一次收缩过程。
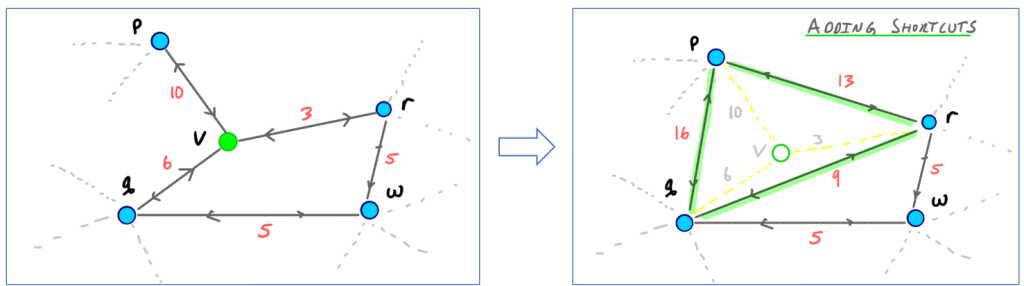
添加快捷边的时机
在一个限制过的搜索空间中(否则需要全局Dijkstra搜索),可以抽象出v对应的传入边uv和传出边vw,计算所有从u通过v到达w的成本P_w,并获取成本的最大值P_max;
在排除v的子图上执行Dijkstra搜索,一旦出现uw最短路大于P_max的情况,说明排除v对搜索结果产生了影响,需要添加一条权重为P_w的快捷边uw,并增加指针uvw(方便后续搜索时回溯具体的最短路径);反之,不添加任何快捷边。
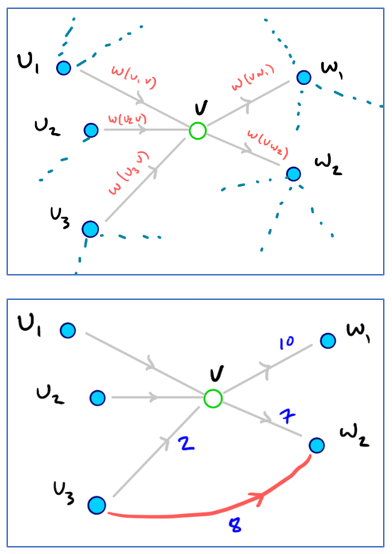
节点收缩的优先级(针对CH原算法)
可以证明,对于任何指定的节点收缩顺序,最终的路径搜索结果都是正确的。但更合适的收缩顺序必然会导致更优秀的查询速度。确定节点初始优先级通常考虑边差异(Edge Difference)指标,即节点模拟收缩后增加的快捷边和该节点原有边的数量差值;在每次收缩后进行惰性更新(Lazy Updating),以维护优先队列的性能。
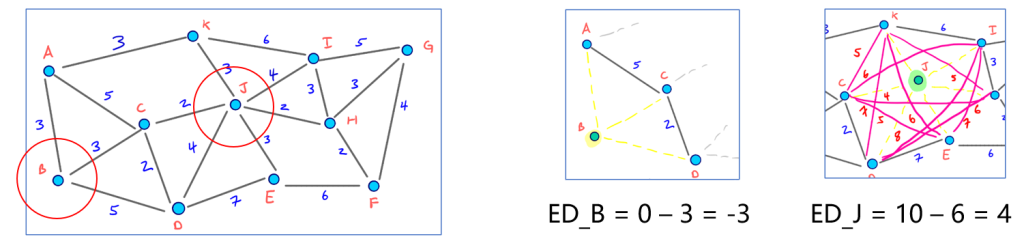
收缩结果
添加的三条快捷边AJ、AH、AF:
节点层级的编排:
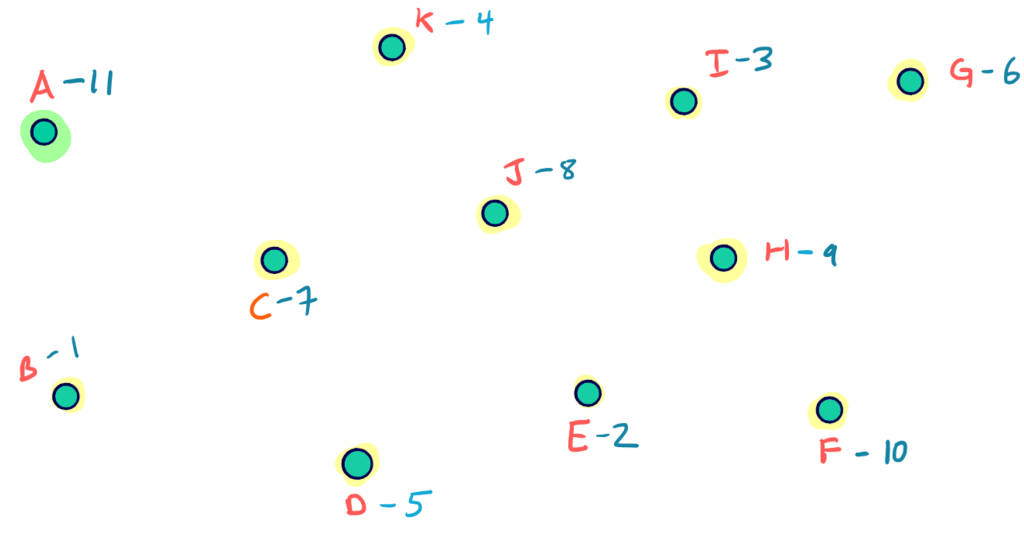
CH算法原理:查询
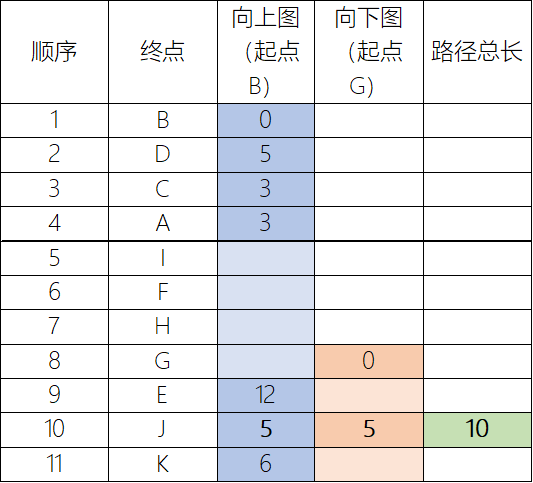
注:本节所选演示图片来自https://jlazarsfeld.github.io/ch.150.project/sections/10-ch-query/
搜索算法:双向Dijkstra的CH版本
和普遍的双向Dijkstra方法不同,CH算法中使用的修改版本只需要在两个方向上的子图,即向上图(upward graph)和向下图(downward graph)中进行搜索。
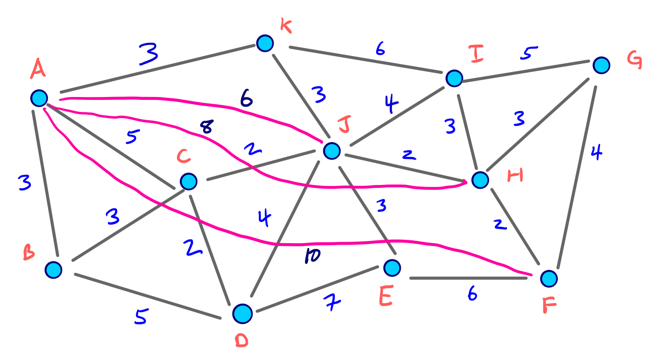
以B至G的路线为例,对应的向上图和向下图(均向层级更高的方向拓展):
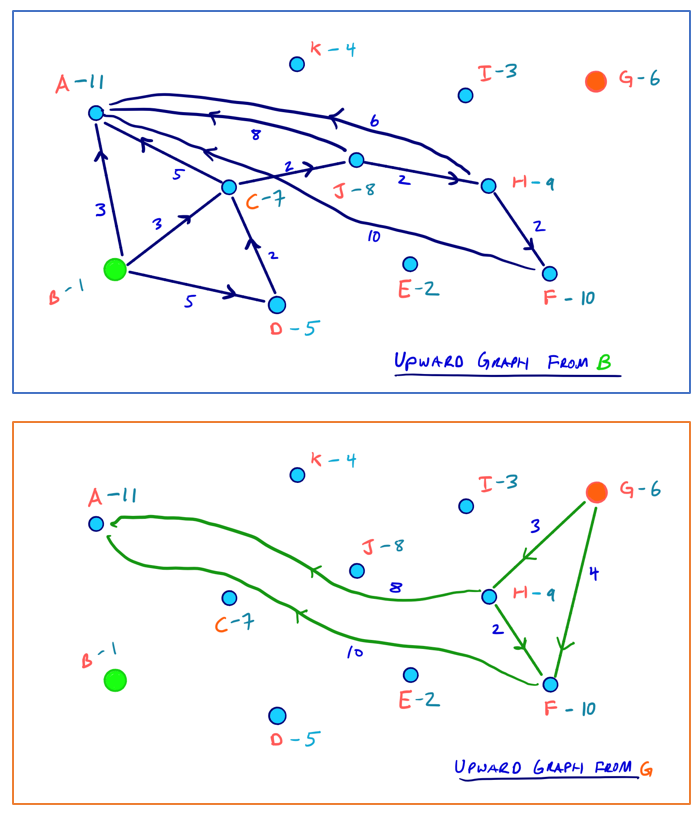
由于拥有完整的节点排序,因此向上图、向下图分别可以表示成有向无环图(DAG)的形式,此时就表现出了收缩顺序的层次(Hierarchy)性质。
原始双向Dijkstra:考虑20 + 20 = 40条边
CH预处理后:考虑11 + 5 = 16条边
附:在上海路网中的一次测试(搜索时跳过了98.9%的节点):

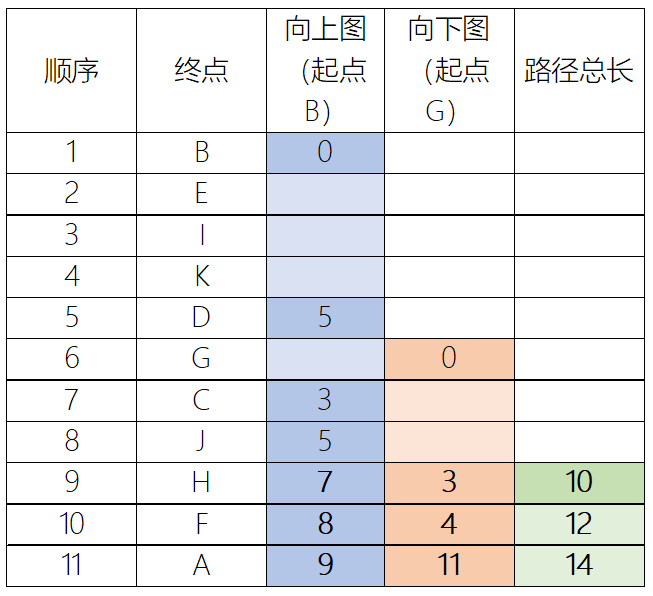
搜索结果
获取完整的最短路径结果需要回溯Dijkstra父边指针,如果涉及快捷边(此处未涉及)也回溯对应指针。
改进CH的思考
动态权重:CCH
CCH(Customizable Contraction Hierarchies)算法:
- CCH使用一个不依赖于边权重的节点顺序,这一顺序根据图的拓扑结构确定(通过嵌套划分法, Nested Dissection);因此边权重是可以实时定制的。
- CCH在定制阶段根据拓扑排序的逆序遍历所有uvw(uw间即为shortcut)三角形,检查其是否有效,失效则更新该shortcut的权重。
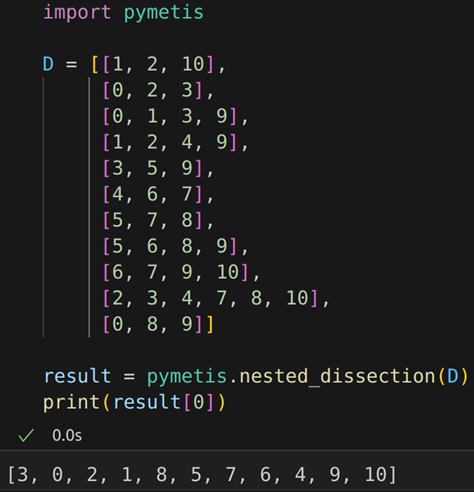
以下是嵌套划分法的实例演示。
利用Metis的嵌套划分方法获取收缩顺序
注:请在Linux环境下利用pymetis库进行实验
收缩并添加快捷边
查询结果
其他思考
变更规则
将权重从单一规则(时耗、长度等)变为多因素的函数,如综合考虑不同个体在时间、费用、拥堵、碳排放等方面的耐受程度,在CCH的基础上提供更加定制化的路径搜索。
组合算法
CH在路网本身层次不明显时(如相对独立的小型园区、住宅区等)加速效果可能较弱,因此可考虑通过一定的方式隔离出相关区域,在这些区域中接入其他路由算法。
附录:图搜索算法CH的Python实现
CH模型代码
import networkx as nx
from tqdm import tqdm
import math
import time
class ContractionHierarchies(object):
def __init__(self, graph):
self.graph = graph
self.G = nx.Graph()
self.imp_pq = list()
self.order = 0
def connect(self):
graph_parameters = self.graph.readline().split('\t')
vertices_number = int(graph_parameters[0], base=10)
for _ in range(vertices_number):
self.G.add_node(_ + 1, contracted=False, imp=0, level=0, contr_neighbours=0)
edge = self.graph.readline()
while edge:
edge_parameters = edge.split()
source_node = int(edge_parameters[0], base=10)
target_node = int(edge_parameters[1], base=10)
edge_weight = int(edge_parameters[2], base=10)
found_exist = False
for _ in self.G[source_node]:
if target_node == _:
self.G[source_node][target_node]['weight'] = min(self.G[source_node][target_node]['weight'],
edge_weight)
found_exist = True
break
if not found_exist:
self.G.add_edge(source_node, target_node, weight=edge_weight)
edge = self.graph.readline()
def get_importance(self, curr_node):
edges_incident = len(self.G[curr_node])
shortcuts = 0
seen_before = list()
for _ in self.G[curr_node]:
for __ in self.G[curr_node]:
pair = sorted((_, __))
if _ == __ or (pair in seen_before):
continue
seen_before.append(pair)
if (not self.G.nodes[_]['contracted']) and (not self.G.nodes[__]['contracted']):
shortcuts += 1
edge_difference = shortcuts - edges_incident
return edge_difference + 2 * self.G.nodes[curr_node]['contr_neighbours'] + self.G.nodes[curr_node]['level']
def get_max_edge(self, curr_node):
ret = 0
for _ in self.G[curr_node]:
for __ in self.G[curr_node]:
if _ != __ and not self.G.nodes[_]['contracted'] and not self.G.nodes[__]['contracted']:
ret = max(ret, self.G[curr_node][_]['weight'] + self.G[curr_node][__]['weight'])
return ret
def check_witness(self, n, _, curr_node, mx):
dij_pq = list()
dij_pq.append((0, _))
dij_dist = dict()
dij_dist[_] = 0
iter = int(250 * (n - self.order) / n)
while len(dij_pq) > 0 and iter > 0:
iter -= 1
curr_dist_pair = min(dij_pq, key=lambda pair: pair[0])
curr_dist = curr_dist_pair[0]
a = curr_dist_pair[1]
dij_pq.remove(curr_dist_pair)
if curr_dist > dij_dist[a]:
continue
for p in self.G[a]:
new_dist = curr_dist + self.G[a][p]['weight']
if p != curr_node and not self.G.nodes[p]['contracted']:
if p not in dij_dist or dij_dist[p] > new_dist:
if p not in dij_dist:
if new_dist < mx:
dij_dist[p] = new_dist
dij_pq.append((new_dist, p))
else:
if dij_dist[p] < mx:
dij_dist[p] = new_dist
dij_pq.append((new_dist, p))
for v in self.G[curr_node]:
if v != _ and not self.G.nodes[v]['contracted']:
new_w = self.G[_][curr_node]['weight'] + self.G[curr_node][v]['weight']
if (v not in dij_dist) or dij_dist[v] > new_w:
self.G.add_edge(_, v, weight=new_w)
def contract_node(self, curr_node, n):
mx = self.get_max_edge(curr_node)
seen_before = list()
for _ in self.G[curr_node]:
for __ in self.G[curr_node]:
if (self.G.nodes[_]['contracted']) or (self.G.nodes[__]['contracted']):
continue
pair = sorted((_, __))
if _ == __ or pair in seen_before:
continue
seen_before.append(pair)
self.check_witness(n, _, curr_node, mx)
for _ in self.G[curr_node]:
self.G.nodes[_]['contr_neighbours'] += 1
self.G.nodes[_]['level'] = max(self.G.nodes[_]['level'], self.G.nodes[curr_node]['level'] + 1)
def set_order(self):
n = len(self.G.nodes)
for _ in tqdm(range(n)):
self.imp_pq.append((self.get_importance(_ + 1), _ + 1))
order = 1
lazy_update_counter = 0
contracted_num = 0
while len(self.imp_pq) > 0:
curr_node_imp_pair = min(self.imp_pq, key=lambda pair: pair[0])
curr_node = curr_node_imp_pair[1]
self.imp_pq.remove(curr_node_imp_pair)
new_imp = self.get_importance(curr_node)
if (len(self.imp_pq) == 0) or (
new_imp - min(self.imp_pq, key=lambda pair: pair[0])[0] <= 10) or lazy_update_counter >= 5: # 这些参数的设置在某种程度上会影响结果的准确性和预处理效率。根据博主的测试,在上海路网中当前这些参数会导致CH算法最短路计算结果出现0.4%的误差,应该在允许范围以内。选择参数的原则应该是让准确性和效率处于一个平衡。
lazy_update_counter = 0
self.G.nodes[curr_node]['imp'] = order
order += 1
self.G.nodes[curr_node]['contracted'] = True
self.contract_node(curr_node, n)
contracted_num += 1
if len(self.imp_pq) <= 2000 and len(self.imp_pq) % 100 == 0:
print(len(self.imp_pq), 'iters remains')
else:
self.imp_pq.append((new_imp, curr_node))
lazy_update_counter += 1
def get_distance(self, source, target):
SP_s = dict()
parent_s = dict()
unrelaxed_s = list()
for node in self.G.nodes():
SP_s[node] = math.inf
parent_s[node] = None
unrelaxed_s.append(node)
SP_s[source] = 0
while unrelaxed_s:
node = min(unrelaxed_s, key=lambda node: SP_s[node])
unrelaxed_s.remove(node)
if SP_s[node] == math.inf:
break
for child in self.G[node]:
if self.G.nodes[child]['imp'] < self.G.nodes[node]['imp']:
continue
distance = SP_s[node] + self.G[node][child]['weight']
if distance < SP_s[child]:
SP_s[child] = distance
parent_s[child] = node
SP_t = dict()
parent_t = dict()
unrelaxed_t = list()
for node in self.G.nodes():
SP_t[node] = math.inf
parent_t[node] = None
unrelaxed_t.append(node)
SP_t[target] = 0
while unrelaxed_t:
node = min(unrelaxed_t, key=lambda node: SP_t[node])
unrelaxed_t.remove(node)
if SP_t[node] == math.inf:
break
for child in self.G[node]:
if self.G.nodes[child]['imp'] < self.G.nodes[node]['imp']:
continue
distance = SP_t[node] + self.G[node][child]['weight']
if distance < SP_t[child]:
SP_t[child] = distance
parent_t[child] = node
minimum = math.inf
merge_node = None
for _ in SP_s:
if SP_t[_] == math.inf:
continue
if SP_t[_] + SP_s[_] < minimum:
minimum = SP_s[_] + SP_t[_]
merge_node = _
return minimum, merge_node, SP_s, SP_t, parent_s, parent_t
def route_dijkstra(self, parent, node):
route = list()
while node != None:
route.append(node)
node = parent[node]
return route[:: -1]
def see_full_route(self, source, target, show_details=False):
print('>>> search route from vertices ' + str(source) + ' to ' + str(target))
time_start = time.time()
minimum, merge_node, SP_s, SP_t, parent_s, parent_t = self.get_distance(source, target)
print('shortest distance: ', minimum)
route_from_target = self.route_dijkstra(parent_t, merge_node)
print('route from target: ', route_from_target)
route_from_source = self.route_dijkstra(parent_s, merge_node)
print('route from source: ', route_from_source)
route = route_from_source + route_from_target[:: -1][1:]
time_end = time.time()
print('entire route: ', route)
print('request time cost: ', str(time_end - time_start))
if show_details:
unvisited = 0
for s_node, s_dist in SP_s.items():
for t_node, t_dist in SP_t.items():
if s_node == t_node and s_dist == t_dist == math.inf:
unvisited += 1
print(f'we have skipped {unvisited} nodes from a graph with {len(self.G)},'
f'so we have skipped {unvisited / len(self.G) * 100}% of the nodes in our search space.')
测试代码
from CH_model import ContractionHierarchies
graph = open("test_network.txt", "r")
ch = ContractionHierarchies(graph)
ch.connect()
ch.set_order()
ch.see_full_route(10, 40)测试文件test_network.txt长这样(取前五行):

第一行是节点数、边数;从第二行开始是边的属性:起始节点、终止节点和边权重。
小改进
因为关于双向Dijkstra的方法get_distance()的代码写得太烂,于是寻求Bing的帮助,果然被锤了:

get_distance()这段代码可以替换成:
def dijkstra(self, source, SP, parent):
unrelaxed = [(0, source)]
while unrelaxed:
dist, node = heapq.heappop(unrelaxed)
if SP[node] == math.inf:
SP[node] = dist
for child in self.G[node]:
if self.G.nodes[child]['imp'] < self.G.nodes[node]['imp']:
continue
distance = SP[node] + self.G[node][child]['weight']
if distance < SP[child]:
SP[child] = distance
parent[child] = node
heapq.heappush(unrelaxed, (distance, child))
def get_distance(self, source, target):
SP_s = {node: math.inf for node in self.G.nodes()}
parent_s = {node: None for node in self.G.nodes()}
SP_s[source] = 0
SP_t = {node: math.inf for node in self.G.nodes()}
parent_t = {node: None for node in self.G.nodes()}
SP_t[target] = 0
self.dijkstra(source, SP_s, parent_s)
self.dijkstra(target, SP_t, parent_t)
minimum = math.inf
merge_node = None
for node in SP_s:
if SP_t[node] != math.inf and SP_s[node] + SP_t[node] < minimum:
minimum = SP_s[node] + SP_t[node]
merge_node = node
return minimum, merge_node, SP_s, SP_t, parent_s, parent_t后日谈
显然上述代码实现还有很多的不足。博主在后续推进研究时,将上述代码进行了以下的优化:
- 将其整体修改为基于有向图的方法。毕竟,博主所研究的交通路网领域不可能用无向图来设计导航。这一修改不仅修改了预处理中的局部Dijkstra方法,也使得前向、后向查询变成了两个不同的方法。
- 将其用igraph库重构。networkx库是一个纯Python库,相对于底层为C的igraph来说在很多地方的效率都不尽如人意。重构后,预处理时间缩短为原先的30%。
- 将其套一个Cython的壳。也就是说,只是用Cython重新编译了一遍上述代码,没有修改其中的内容。使用Cython编译后,预处理时间再次缩短10%。
- 改写部分高频使用的函数。比如
check_witness()和前向、后向查询方法中对self.G属性反复引用,将其修改为内部引用,如get_edge_attribute = self.G.es.__getitem__等(注意,这里已经是基于igraph的了),预处理时间再次缩短20%,查询时间缩短40%。 - 当然,除了效率改进,更多的是在场景兼容性上的改进,比如:增加对Turn Cost的考虑及Dynamic Updating策略等。这些已结合进实际交通诱导场景,并就后者申请了相关专利。
博主暂时不会贴出最终版本的代码,谁知道还会不会在后面的研究中派上用场:P。
