简介
主成分分析(PCA)算法是以下两个特征提取需求的践行形式:
- 降维前样本到降维后超平面应足够近。即:超平面上的投影应尽量接近原始数据点。
- 超平面上的投影应尽可能分开。即:数据点之间的差异(此处指方差)应该尽可能大,使得降维后的数据其结构依然保持应有的丰富性。
利用PCA算法将样本由n维降低到n'维,最原始的流程为:
样本中心化 -> 求中心化后的协方差矩阵 -> 求协方差矩阵的特征值、特征向量 -> 挑出前n'个(即最大的n'个)特征值对应的特征向量,将其组建为特征向量矩阵W -> 对每个样本x(i),进行降维变换:z(i) = WTx(i)。
这样做的原因是,由于特征值减小特别的快,前n'个特征值实际上包含了大部分的特征信息,因此可以将其作为主成分,用于近似描述样本矩阵。
优化:奇异值分解(SVD)
参考文献:https://zhuanlan.zhihu.com/p/29846048
PCA算法的实现实际上可以借助SVD的原理。SVD是一种矩阵分解技术,可以将一个矩阵分解成三个矩阵的乘积:
A = U∑VT
其中U、V为正交矩阵,∑为对角矩阵,对角线上是奇异值。
算例
利用numpy对矩阵A:[[0 1] [1 1] [1 0]]进行奇异值分解。
import numpy as np
def svd_by_library(A):
return np.linalg.svd(A)
def svd_manual(A):
AtA = np.dot(A.T, A)
AAt = np.dot(A, A.T)
# 特征值分解
eigvals_V, V = np.linalg.eig(AtA)
eigvals_U, U = np.linalg.eig(AAt)
# 奇异值
Sigma = np.sqrt(eigvals_V)
# 确保U和V是正交矩阵
U = np.linalg.qr(U)[0]
V = np.linalg.qr(V)[0]
return U, Sigma, V.T
if __name__ == '__main__':
A = np.array([[0, 1], [1, 1], [1, 0]])
# U, Sigma, Vt = svd_by_library(A) # 库方法
U, Sigma, Vt = svd_manual(A) # 手写方法
# 生成奇异值矩阵
Sigma_full = np.zeros((A.shape[0], A.shape[1]))
np.fill_diagonal(Sigma_full, Sigma)
print(f'Matrix A:\n{A}\nMatrix U:\n{U}\nMatrix Sigma:\n{Sigma_full}\nMatrix Transposed V:\n{Vt}')与PCA的关联
PCA使用的特征向量矩阵即为这里的右奇异矩阵V。更进一步地,SVD的实现算法可以不先求得协方差矩阵而得到V。也就是说,PCA算法在利用SVD实现时,可以不用做上面提到的特征分解。这也是scikit-learn中PCA方法的原理。
import numpy as np
A = np.array([[0, 1], [1, 1], [1, 0]])
A_centered = A - np.mean(A, axis=0) # 中心化数据
U, Sigma, Vt = np.linalg.svd(A_centered, full_matrices=False) # 进行SVD分解
principal_components = Vt.T # 获取主成分Scikit-learn中的PCA类
参考文献:
https://zhuanlan.zhihu.com/p/33191810
https://zhuanlan.zhihu.com/p/414275930
参数
该类中有两个重要参数:
n_components: 指定降维后的特征维度数目(n')。whiten: 是否进行白化,默认False。
这里的白化操作是指对降维后数据的每个特征归一化,使得方差均为1。如有后续的数据处理,则可以考虑白化。其具体实现为:用特征向量矩阵的转置左乘原始数据矩阵(旋转变换),再对转换后矩阵每一维除以对应特征值(即方差)。
算例
用经典的鸢尾花数据集展示该类的使用方法。
先不进行降维,看看数据投影后的方差分布。
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
iris = load_iris().data
pca = PCA(n_components=4)
pca.fit(iris)
print(pca.explained_variance_) # 各主成分的方差值
print(pca.explained_variance_ratio_) # 各主成分方差值占总方差值的比例Explained variance ratio的计算结果为:
| 0.92461872 | 0.05306648 | 0.01710261 | 0.00521218 |
由此也可以印证,通常情况下头部的特征包含了绝大部分的特征信息。
将原始数据降至三维,并绘制降维后的数据分布图。
from pyecharts.charts import Scatter3D
pca_3d = PCA(n_components=3)
iris_3d = pca_3d.fit_transform(iris)
print(pca_3d.explained_variance_ratio_)
# 绘图
scatter3d = Scatter3D()
scatter3d.add(series_name='iris_3d', data=iris_3d.tolist())
scatter3d.render('iris_3d.html')Explained variance ratio的计算结果为:
| 0.92461872 | 0.05306648 | 0.01710261 |
这个结果完全可以预料。四维原始数据投影到三维,被舍弃的肯定是最后一个特征。
使用上面的三维数据,继续降至二维:
pca_2d = PCA(n_components=2)
iris_2d = pca_2d.fit_transform(iris_3d)
print(pca_2d.explained_variance_ratio_)Explained variance ratio的计算结果为:
| 0.92946326 | 0.05334452 |
嗯,怎么和上面的前两个特征结果有差异?
因为从三维到二维的过程中,显然已经丢失了第四个特征的信息,这就导致了累积误差的产生。所以正确的做法应该是直接进行从高维到目标维度的降维操作。
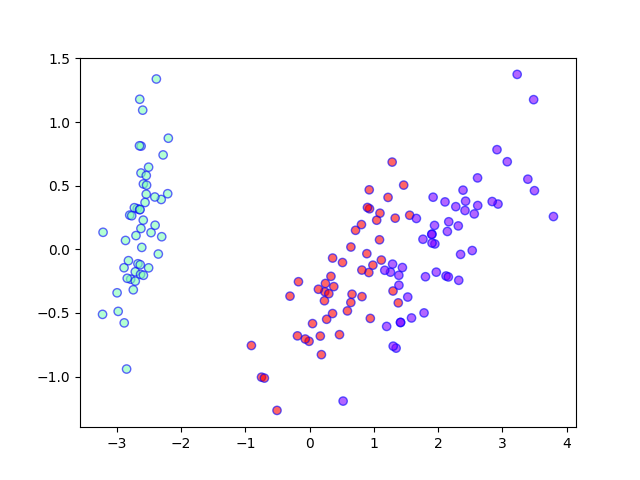
直接从四维降到二维,并且利用KMeans在降维后数据集中执行无监督分类:
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
pca_2d = PCA(n_components=2)
iris_2d = pca_2d.fit_transform(iris)
kms = KMeans(n_clusters=3) # sklearn默认的其实是KMeans++
kms.fit(iris_2d)
pred_labels = kms.labels_
plt.scatter(iris_2d[:, 0], iris_2d[:, 1], c=pred_labels, cmap='rainbow', alpha=0.6, edgecolors='b')
plt.show()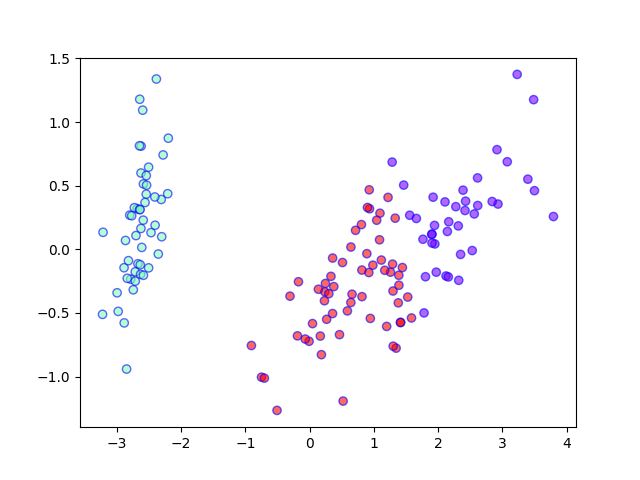
将这一结果再与真实类别对比,看看PCA特征提取的真实效果如何:
true_labels = load_iris().target
map_dict = {0: 1, 1: 2, 2: 0}
true_labels = map(lambda label: map_dict[label], true_labels) # 稍微调整一下类别顺序,方便对比
plt.scatter(iris_2d[:, 0], iris_2d[:, 1], c=list(true_labels), cmap='rainbow', alpha=0.6, edgecolors='b')
plt.show()